Your traffic is down. Your growth team is panicking. And your product metrics might be telling you absolutely nothing useful.
Kyle Poyar's 2025 State of B2B GTM report uncovered something fascinating: Webflow's aggregate traffic is declining while their business is accelerating. ChatGPT referrals convert at 24% compared to 4% from Google. Two-thirds convert within 7 days.
This isn't a Webflow-specific anomaly. It's what happens when AI search reshapes discovery.
The death of aggregate traffic as a north star
Google AI overviews are fundamentally changing what traffic even means. Low-intent, high-volume queries that used to pad your metrics are vanishing into AI-generated answer boxes. The traffic that remains is radically higher quality.
"A lot of our lower value and lower intent traffic has gone down, but there's higher quality traffic occurring even as the aggregate declines," Josh Grant, Webflow's VP of Growth, told Poyar.
Aggregate traffic is completely misleading without a quality metric. You're not measuring growth. You're measuring noise. This is a symptom of a broader problem with how metrics fail to capture what actually matters.
The new metrics layer: Visibility, comprehension, conversion
If traditional traffic metrics don't work, what does? Webflow built a three-layer framework for AI discovery:
Visibility: How often you're cited in AI search results. Not impressions or rankings. Citations. They track this across ChatGPT, Perplexity, and Claude using tools like Profound.
Comprehension: How accurately AI models describe your product versus competitors. Grant's team prompts multiple LLMs side by side to audit their narrative. If the description is wrong, they know where to improve.
Conversion: Signup rates and time-to-conversion from LLM-referred traffic. High-intent traffic doesn't just convert better. It converts faster.
Traditional SEO dashboards track rankings and clicks. This framework tracks whether AI systems understand, trust, and recommend you.
What this means for product teams
This isn't just a marketing problem. Your product's narrative has to work for both humans and AI models. How ChatGPT describes your product when users aren't searching for you by name is your new positioning test.
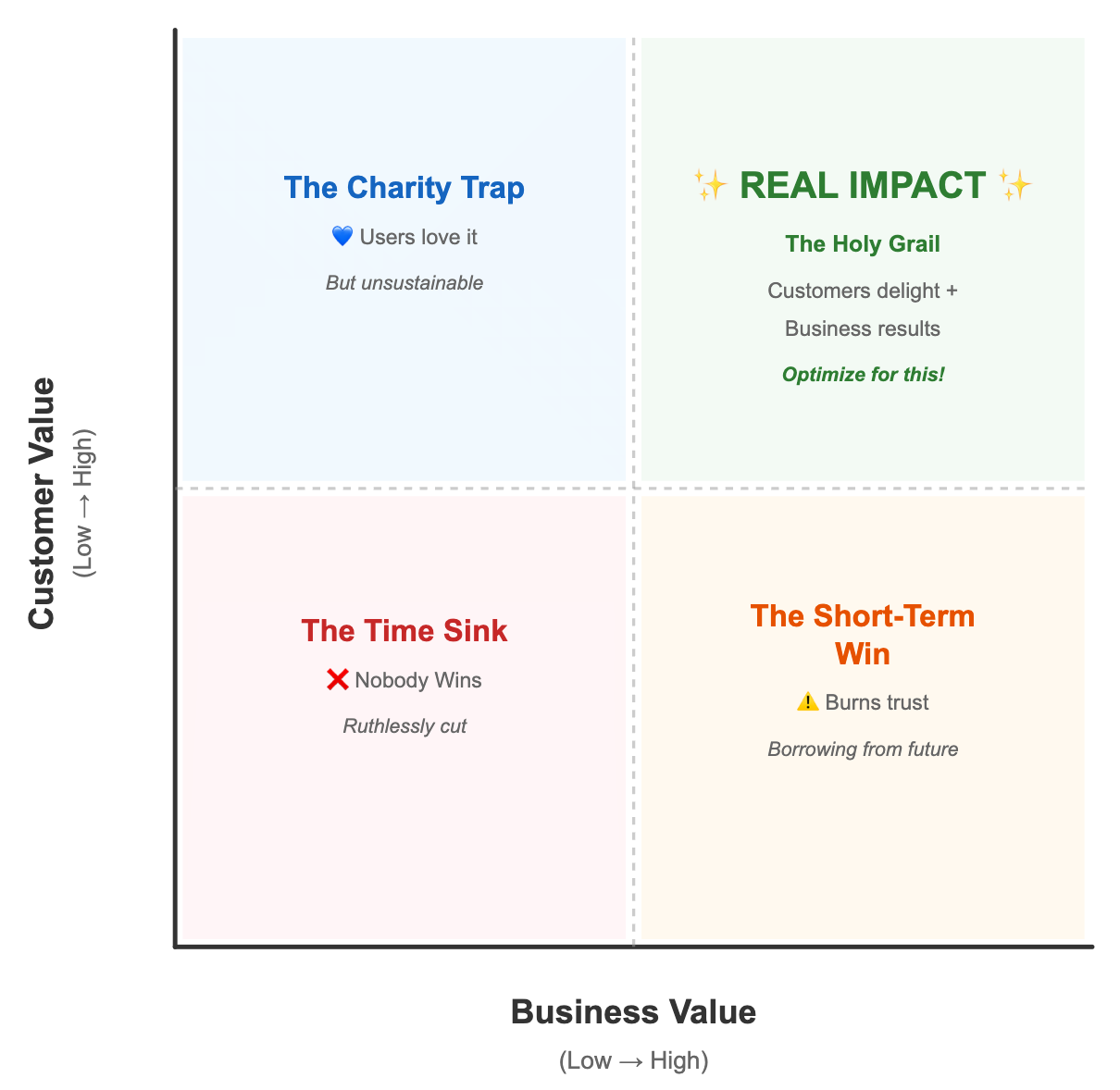
The metrics you're optimizing for might be pushing you in the wrong direction. Volume-based goals (MAU, traffic, impressions) reward low-quality interactions. Quality-based goals (conversion rate, time-to-convert, citation frequency) reward relevance and trust. Instead of chasing traffic, map your work by customer value and business value to reveal what's actually moving the needle.
AI discovery is volatile, not fixed like Google rankings. Grant's observation: "Every query is a fresh model run that reshuffles sources in real time based on context, trust, and recency." You can't optimize once and coast.
Teams treating AI discovery as optional or as a one-time project will spend the next year explaining why their metrics look strong but their pipeline has dried up.
The question you should be asking
If aggregate traffic is misleading, what quality metrics are you tracking today? If you're not tracking quality separately from volume, how do you know whether your growth is real or just noise?
The shift from traffic to intent, from volume to quality, from rankings to comprehension is not a future state. It's happening now. Webflow's data proves it. The question is whether your metrics can see it.