
Early Experience: A Different Approach to Agent Training

AI agents are currently in use, handling customer service interactions, automating research workflows, and navigating complex software environments. But training them remains resource-intensive: you either need comprehensive expert demonstrations or the ability to define clear rewards at every decision point.
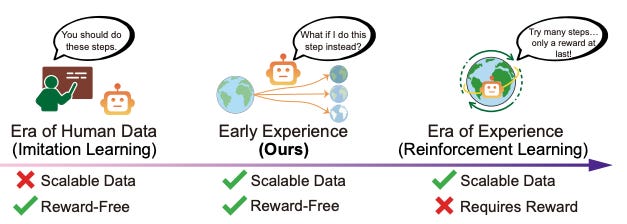
Meta’s recent research explores a third path. Agent Learning via Early Experience proposes agents that learn from their own rollouts—without exhaustive expert coverage or explicit reward functions. It’s early, but the direction is worth understanding.
(Source: Meta’s research paper)
Current Training Constraints
Today’s agent training follows two primary approaches, each with different resource demands:
Imitation Learning works well when you can provide thorough expert demonstrations. The challenge isn’t the method—it’s achieving comprehensive coverage across the scenarios your agent will encounter in production.
Reinforcement Learning delivers strong results when you can define verifiable rewards. But most real-world agent tasks like content creation, customer support, and research assistance don’t have clear numerical rewards at each step. You’re left with engineering proxy metrics that may not capture what actually matters.
Neither approach is inherently limited. Both are constrained by what they require: extensive demonstrations or definable rewards.
What Early Experience Proposes
Meta’s research introduces a training paradigm where agents use their own exploration as the learning signal. Two mechanisms drive this:
Implicit World Modeling: The agent learns to predict what happens after it takes actions. These predictions become training targets—future states serve as supervision without external reward signals. The agent builds intuition about environmental dynamics through its own experience.
Self-Reflection: The agent compares its actions to expert alternatives and generates natural language explanations for why different choices would be superior. It’s learning from its suboptimal decisions through structured comparison.
The core idea: an agent’s own rollouts contain a training signal. You don’t need a human expert for every scenario or a reward function for every decision.
Whether this scales to production environments across different domains remains an open question.
The Research Numbers
In controlled benchmark environments, Early Experience showed meaningful gains over imitation learning: +18.4% on e-commerce navigation tasks, +15.0% on multi-step travel planning, and +13.3% on scientific reasoning environments.
When used as initialization for reinforcement learning, the approach provided an additional +6.4% improvement over starting from standard imitation learning.
These are research benchmarks, not production deployments. The question is whether these gains transfer to real-world complexity and whether the approach works across different agent domains.
What Changes If This Materializes
If this training paradigm proves viable at scale, several implications follow:
Training economics shift: Less dependence on comprehensive expert demonstration coverage could reduce the human-in-the-loop burden during agent development. You’re trading labor-intensive curation for computation-intensive self-supervised learning.
Deployment pathway evolves: Start with Early Experience training, deploy and collect production data, then layer reinforcement learning for further optimization where rewards are verifiable. Each stage builds on actual agent experience rather than static expert datasets.
Infrastructure requirements matter: The approach needs agents with enough initial capability to generate meaningful rollouts. It’s most applicable in domains with rich state spaces like web navigation, API interactions, and complex planning tasks.
This isn’t a universal solution. It’s likely domain-dependent, and we don’t yet know where the boundaries are.
The Question Worth Asking
It’s too early to call this a paradigm shift. But it represents a direction worth watching: agents learning through structured exploration of their own experience rather than pure imitation or reward maximization.
The research suggests that training agents might become less labor-intensive. Whether that transfers from research benchmarks to production systems is still uncertain.
For teams building agents: what experiments could validate whether self-supervised learning works for your specific use cases? The window between “interesting research” and “table stakes capability” has a way of closing faster than expected.